Bridging the Gap: Combining Ontologies and AI for Smarter Building Metadata Mapping
April 1, 2025
By Nick Gayeski and Sian Kleindienst
This post is going to be a nerdy one, but sometimes we need to ‘lean in’ to who we are. In deploying Clockworks on sites around the world, challenges often occur applying metadata to any given building, system, or equipment. Most of the time, the issue is that there is no structured metadata in the building. These days, however, there is an increasingly common situation in which partial metadata, or metadata partially following a standard, exists in the building. This happens especially on Haystack tagged buildings that didn’t strictly follow Haystack protos —i.e. tag set standards, or that extended those tags with their own.
Incomplete Tags and Imperfect Mappings
As tagging and data layer concepts gain market traction, there is in fact a dirty secret. If the ontology isn’t complete for the use case you want to fill, then there can be hidden costs or unfulfilled expectations of efficiencies gained. The solution is to leverage AI to not only help create the core information model from scratch (like we did) but to also fill in gaps or discrepancies where they exist.
Let’s explore the latter.
In many buildings, there is often a partial or imperfect mapping between a Haystack tag set and the point types within the Clockworks ontology—meaning the mapping isn’t one-to-one. This could be because of incomplete mapping of a specific site.
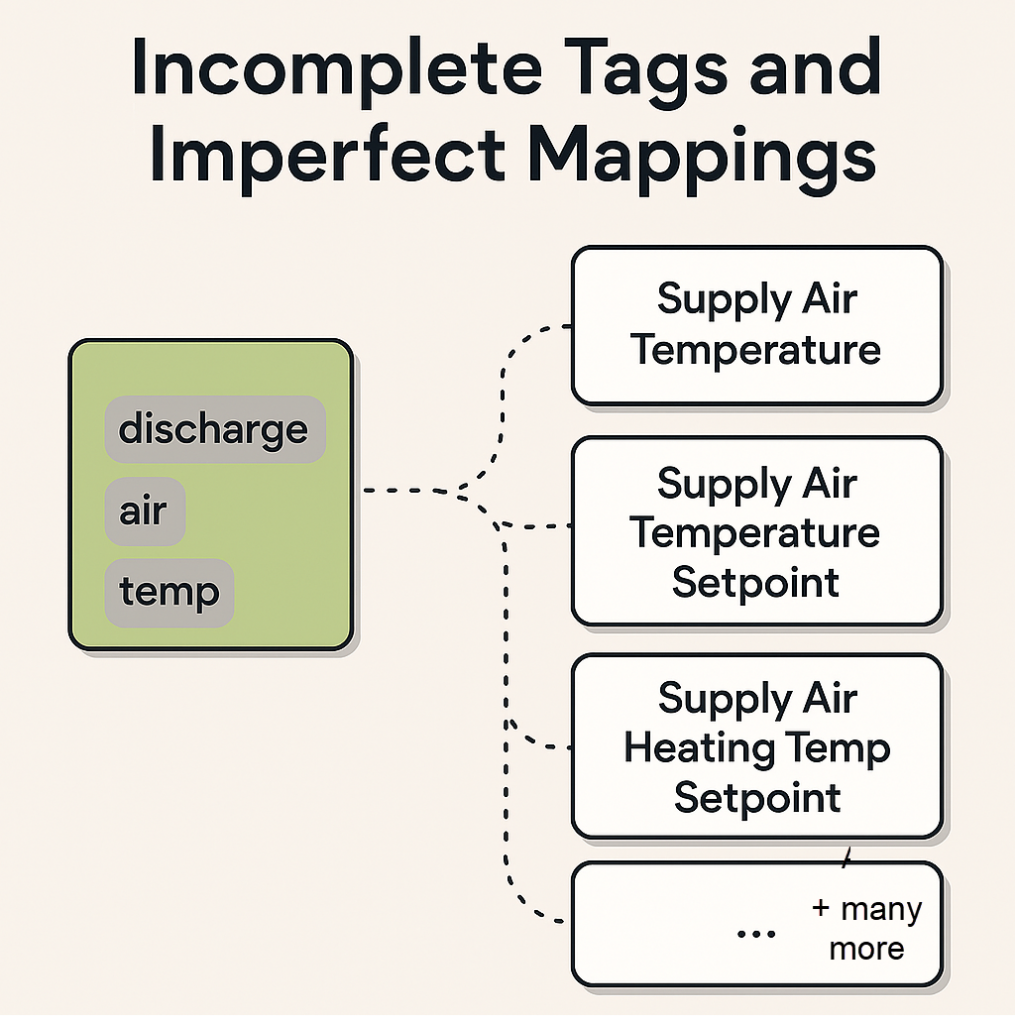
For example, a point that has the Haystack tags “discharge,” “air,” and “temp” could map to 21 possible point types in Clockworks, not just one. A Supply Air Temperature point may only have the tags “discharge,” “air,” and “temp” simply because not enough care was taken to completely represent the point, where it should have included a “sensor” tag. We see this frequently when bulk tagging tools are used without a use case in mind.
This lack of one-to-one mapping can also be caused by two ontologies not completely overlapping in the concepts or real-world data they represent, leading to an “ontological impedance mismatch.” For example, if one ontology has a representation for the concept of a Cooling Tower Status and the other has the concept of Cooling Tower Status and Cooling Tower Spray Status, the first ontology may lack sufficient tagging to know that a point is definitively a Cooling Tower Status and not the Spray Status. In other words, one ontology distinguishes between the two concepts and the other does not. This kind of mismatch creates ambiguity in mapping between ontologies.
The problem this creates is the possibility for false negatives and false positives in the Cooling Tower diagnostics. We wouldn’t want to miss a problem that the cooling tower spray is on when it shouldn’t be because we assumed the status was just for general. Nor would we want to flag problems related to the cooling tower fans, approach, or any other characteristics because we thought that ‘spray status’ was the ‘status’. So, the distinction is important based on what the application is trying to do with the metadata.
When these situations arise, be it an imperfect mapping or an ontological impedance, there is value in combining prescriptive mapping with large language model (LLM) machine learning methods—i.e. artificial intelligence (AI)—to clarify the meaning of metadata.
Prescriptive Ontology Mapping
The foundational starting point, as described above, is to use the combinations of Haystack tags on points (call them tag sets, protos, or xeto-types) to narrow down the possible list of point types that the point could “be” in our ontology. When there is a one-to-one match, things are simple. However, in some cases, the tag set just narrows down the list to a set of several different point types that we call “allowed types,” as in the example described above about Cooling Tower Status and Spray Status. Note that Haystack is of course extensible in a way that the “spray” could be represented, it just may not have been defined for all to use yet or it may only be used by certain modelers.
The situation on the ground is that ‘taggers’ don’t often consider these nuances unless there is a specific use case in mind. Furthermore, even when a user follows the best guidance, the standard ‘protos’ might be limited by the most common situations in the field that ‘rose’ to the importance of being defined as a standard ‘proto’.
When we onboard Clockworks, we are laser focused on the metadata that is required for analytics. Project Haystack is thankfully evolving to include validation tools, which will leverage vendor defined “xeto-types” that explicitly represent the tags and metadata required on a Haystack modeled site to fulfill a specific use case by a specific application like Clockworks. At a conceptual level, these become like “protos,” but specifically defined for a use case, application, or device.
Regardless, this initial step is a more prescriptive mapping between ontologies, such as Haystack tag sets and related point types and equipment types in Clockworks.
LLM Based Inference (AI, Yay!)
Now comes the fun part. We have trained an inference engine using an LLM to guess the point types and equipment types of points and devices discovered from building automation systems. We can do this from scratch, as is the case when no other ontology has been applied to a building, but we can also do this to reconcile ambiguities and ontological impedance mismatches, i.e. when things just don’t line up one-to-one as described above. This is becoming more and more common.
In that case, an imperfect match can be fed into the inference engine to guess the Clockworks point type but constrain its predictions based on the allowed types indicated by the ontology mapping. We are seeing this more commonly as we connect more and more Haystack tagged sites. This approach gives us the best of both worlds: the ability to use ontology mappings to quickly onboard buildings from Haystack or other ontologies; and the ability to use an LLM-based inference engine to make better guesses when there are partial metadata or imperfect matches. Using the example above, if tags narrowed a point down to the possible point types illustrated above, the constrained LLM model would, based on the point’s name, be very likely to choose the correct point type.
Ontologies and LLMs are Better Together
The bottom line is that the combination of prescriptive mapping between ontologies and the learning boost of LLM-based inference provides the best of both worlds. We can onboard faster because of both semantic modeling and AI by understanding the benefits and applications of each.
Back to blog